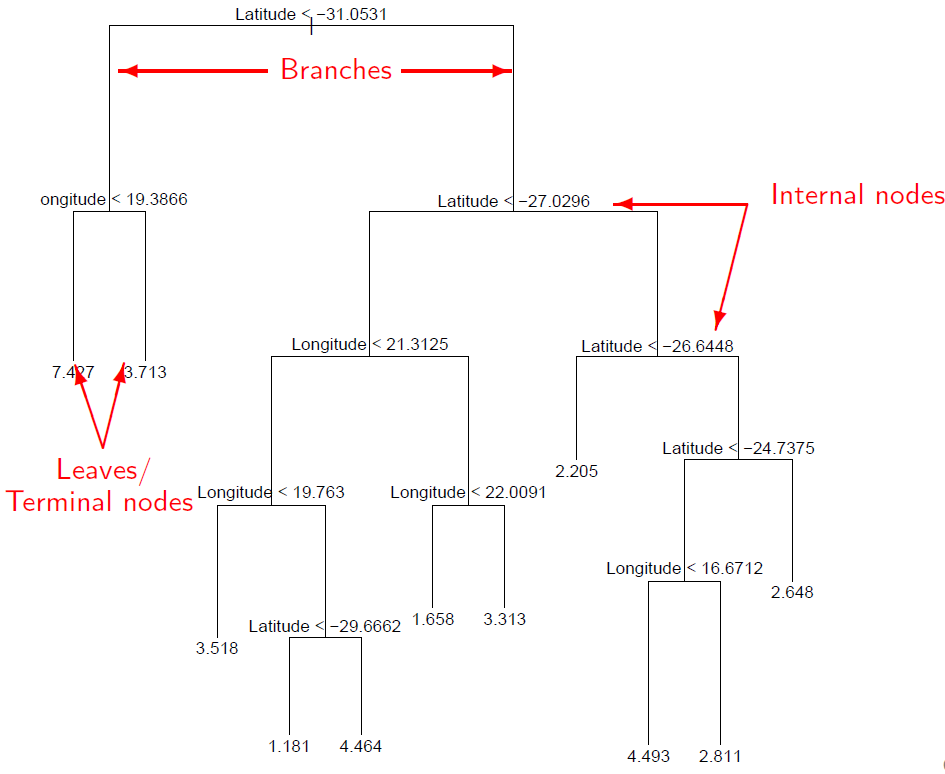
Trees are a type of supervised statistical learning method. Put very simply, trees are methods that relate a response variable y to a set of predictors X, with the aim of predicting the response for future observations. Trees can be seen as an alternative to linear and logistic regression, neural networks, etc.
Ian Durbach provides a brief introduction to the use of classification and regression trees in R.
To learn more about using trees for your own research, see Ian's slides, code and sample data.